library(tidyverse)
library(babynames)Ch.14 Solutions
Prerequisites
14.2.4 Exercises:
These can all be done using raw strings as well.
str_1 <- 'He said "That\'s amazing!"' str_2 <- "\\a\\b\\c\\d" str_3 <- "\\\\\\\\\\\\" str_view(str_1) ## [1] │ He said "That's amazing!" str_view(str_2) ## [1] │ \a\b\c\d str_view(str_3) ## [1] │ \\\\\\There is a Wikipedia page for this character here. It’s a space that prevents an automatic line break.
x <- "This\u00a0is\u00a0tricky" str_view(x) ## [1] │ This{\u00a0}is{\u00a0}tricky x ## [1] "This is tricky"
14.3.4 Exercises:
Code below:
paste0("hi ", NA) ## [1] "hi NA" str_c("hi ", NA) ## [1] NA paste0(letters[1:2], letters[1:3]) ## [1] "aa" "bb" "ac" #str_c(letters[1:2], letters[1:3]) This creates an errorstr_c()is less flexible with certain inputs. This trade-off in flexibility (infectious NA s and requiring same length strings) across the tidyverse limits possible unintended results.
Paste0()is a special case of paste where the separator between results is the empty string. Can recreatepaste()withstr_c()using the the sep argument.str_c('x', 'y') ## [1] "xy" str_c('x', 'y', sep = ' ') ## [1] "x y"Code below:
#1 food = 'hotdog' price = 100 str_c("The price of ", food, " is ", price) ## [1] "The price of hotdog is 100" str_glue("the price of {food} is {price}") ## the price of hotdog is 100 #2 age = 12 country = 'Germany' str_glue("I'm {age} years old and live in {country}") ## I'm 12 years old and live in Germany str_c("I'm ", age, " years old and live in ", country) ## [1] "I'm 12 years old and live in Germany" #3 title = 'Fido' str_c("\\section{", title, "}") ## [1] "\\section{Fido}" str_glue("\\\\section{{{title}}}") ## \\section{Fido}
14.5.3 Exercises:
the babyname dataset is not a row per baby but rather a row per name per year. Therefore we need to compute the sum of n and not the number of occurrences of n. (This is a good example why you should always read documentation and examine a dataset before attempting to pull information from it).
If the length was even I chose 2 characters instead of one.
babynames |> mutate( middle = if_else( str_length(name) %% 2 == 0, str_sub(name, str_length(name) %/% 2, (str_length(name) %/% 2) + 1), str_sub(name, str_length(name) %/% 2 + 1, (str_length(name) %/% 2) + 1) ) ) |> select(name, middle) ## # A tibble: 1,924,665 × 2 ## name middle ## <chr> <chr> ## 1 Mary ar ## 2 Anna nn ## 3 Emma mm ## 4 Elizabeth a ## 5 Minnie nn ## 6 Margaret ga ## 7 Ida d ## 8 Alice i ## 9 Bertha rt ## 10 Sarah r ## # ℹ 1,924,655 more rowsI decided to create a graph of average name length by year and popularity of first letter by year.
babynames |> group_by(year) |> summarise( avg_len =weighted.mean(str_length(name), w = n) ) |> ggplot(aes(year, avg_len)) + geom_smooth(method = 'loess', formula = 'y~x') + labs(x = 'Year', 'Avg. Length')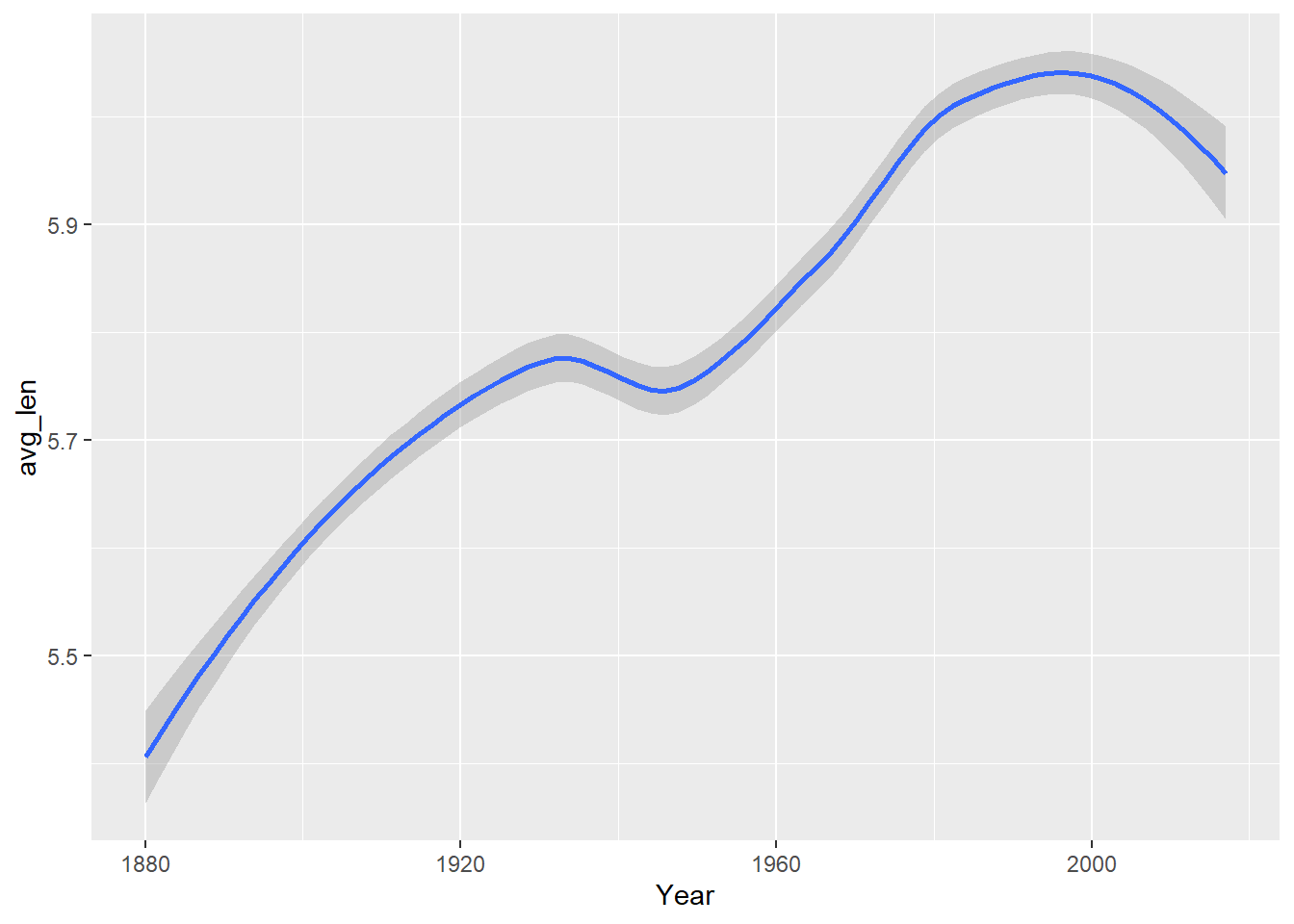
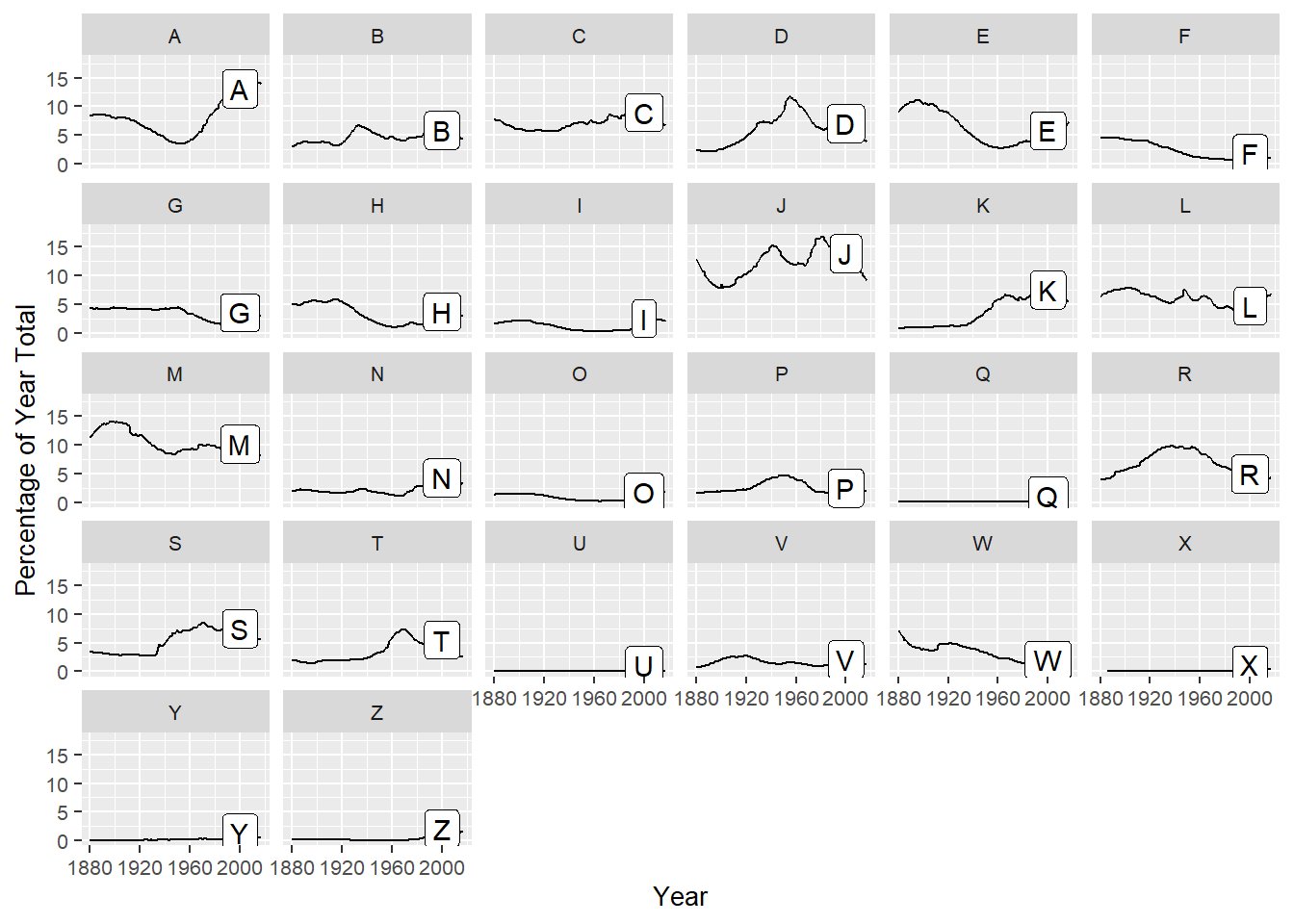
babynames |> mutate(first_letter = str_sub(name, 1, 1)) |> group_by(year, first_letter) |> summarise( occurences = sum(n), .groups = 'drop_last' ) |> mutate( freq = occurences / sum(occurences)*100, label = if_else(year == 2000, first_letter, NA) ) |> ggplot(aes(year, freq, label = label)) + geom_line()+ geom_label(nudge_y = 1, na.rm = TRUE) + facet_wrap(~first_letter) + labs(x = 'Year', y = 'Percentage of Year Total') + theme(text = element_text(size = 10))